GAN
# Tag:
- Source/KU_ML2
GAN(Generative adversarial network)
이 때, G(Generator)가 생성한 데이터 중 D(Discriminator)가 real인지, synthetic하게 만들어 진 데이터인지 판단하지 못하는 경계의 값에 있을 때, 최적 솔루션으로 간주한다.

- G: training data의 distribution을 파악해 noise를 섞어 새로운 synthetic data를 만들어낸다.
- 단순히 여러 이미지를 합성, 평균 내 새로운 이미지를 만든다면 이는 unbiased estimator가 되므로 error는 적어진다.
- 하지만, 이는 곧 단순히 평균 낸 이미지이므로 원하고자 하는 이미지에 벗어날 수 있기에 데이터 샘플의 복잡한 패턴과 다양성을 유지하는 새로운 데이터를 만들어내야 한다.
- D: training data를 이용해 해당 이미지가 real인지, synthetic 이미지인지 파악한다.
- 학습이 진행되면서 real한 이미지를 더 정확히 파악할 수 있다.
- 이렇게 학습된 D를 속일 수 있을 정도의 synthetic data를 만들어내는 G를 학습시켜내는 것이 목표가 된다.
Loss function
- : Random number, random한 noise로 이미지를 생성해낸다.
- : Train data: real data를 의미한다.
- : discriminator에게 real하다고 속일 때가 되며, 이 때 Loss가 제일 작아지는 가 된다.
- 동시에, 로 최적의 이미지를 판단할 수 있는 가 될 때여야 한다.
를 Max 시키는 과정은, Gradient Descent가 아닌 Gradient Ascent를 통해 가 최대한 잘 분간 하도록 을 Back Propagation에 이용하는 과정으로 학습된다.
반대로 에 대해서는, 이 작아지도록 Gradient Descent를 통해 학습한다.
Optimal D(discriminator)
위의 Loss function의 변형에 대하여, optimal discriminator 는
intelgral속 적분 식을 Lagrangier function()은, 곧 optimazation 대상이 된다.
- : 가 되면서, 가 systhetic하다고 판정할 확률이 오른다.
- : 가 되면서, 가 real하다고 판정할 확률이 오른다.
이는, 학습을 통해 하게 되면서 로 수렴하게 되었을 때, 실제 데이터와 생성 데이터간의 차이를 구별할 수 없게 되면서 성공적으로 학습되었음을 의미한다.
gradient ascent 과정을 통해 구한다.
Optimal G(generator)
: 최적의 discriminator가 만들어졌다고 가정하고, 그 discriminator에 대하여 최적의 Generator를 찾는다.
위의 식은, 임을 이용한 것이며, 마지막 식은 결국 Cross Entropy의 꼴로 나타나고, 이는 곧 KL divergence를 의미한다.
따라서, 위의 식이 제일 되려면 , 일 때 KL Divergence이 된다.
이는 일 때, 최적의 Generator가 됨을 의미하는데, Synthetic Data를 거의 Real data처럼 만들어 Disciriminator를 속일 수 있는 것을 의미한다.
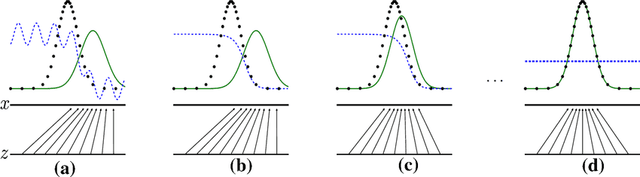
즉, 마지막 그림에서처럼 로 수렴하게 되는 상황이 되어 Systhetic과 Real을 구분하지 못하는 상황이다.
min이 되어야 하는 것이므로, Discriminator와 달리 Gradient Descent를 이용한다.